Current Strategies
Real spiders
Going through all the references returned by a spider takes a lot of time. The human interfacing is usually a disaster; you can see that the programmers found "getting the thing to work" was complicated enough, and they are happy that they can at least deliver some results.Apart from the shear number of references returned a lot are outdated because the network is too large to get a timely overview. AltaVista currently can only visit a site once every seven weeks and they retire sites from their database after a few failed fetch attempts, So it takes months before their database is correct.
The best part of current search engines is that they retrieve their data very quickly. The performance of computers in not the bottle-neck.
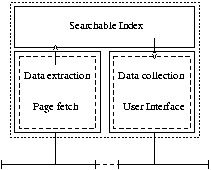 The real spiders, fetch all their pages themselves. They are built on
expensive hardware (huge quantities of disk-space and memory is required) and
complicated software.
The figure left shows the structure of the simplest of those spiders.
Typically, this functionality is spread over a few computers to get
the required performance.
The real spiders, fetch all their pages themselves. They are built on
expensive hardware (huge quantities of disk-space and memory is required) and
complicated software.
The figure left shows the structure of the simplest of those spiders.
Typically, this functionality is spread over a few computers to get
the required performance.
To solve the drawbacks of `real'-spiders, three variations were introduced:
- specialization,
- improving results by reducing the number of searched-sites,
- meta-spiders,
- improving results by combining the results of a few spiders or,
- meta-information,
- adding information to (HTML) pages which is to used by spiders for building indexes.
Specialized spiders
Specialized spiders try to improve the results of a spider by manually adding a pre-Meta-spiders
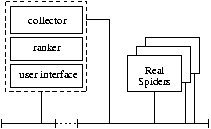 Meta-spiders call many `real'-
Meta-spiders call many `real'-
The meta-spider passes the users request to many real-spiders
which query in their own databases and return appropriate results. The
meta-
This procedure may result in less optimal coverage than that of a single
search engines: the combined performance leads to the average result, a single
engine may be better balanced.
An example of HTML with meta-information:
The Web is also changing from pages mainly being written in HTML into
providing pages in multiple formats. More and more, the documents are
published in doc, XML, pdf, etc. In most of those formats, there is no way
to specify meta-
For all these reasons, this way of adding meta-
But, is everyone willing to become a
librarian? For institutes, universities, and such, the effort to
comply to this system is not too high, but it is a lot to ask small
companies and private
persons to use this system. A large part of the knowledge on
Internet will never be contained in this information-
Next Identifying the Problems.
Meta-information
Steps are taken by a sites maintainer to add information to documents to
facilitate the spiders. HTML meta-tags keywords and
description
are examples for this extensions. In this situation, the publisher of the
document is adding human intelligence.
<HTML>
<HEAD>
<TITLE>Wildlife in Holland</TITLE>
<META NAME=keywords CONTENT="bears, apes, rabbits">
<META NAME=description CONTENT="An overview of
wildlife in The Netherlands.">
<BODY>
....
The NAME-parameters of the META are not officially
standardized, but are commonly used. Most spiders treat them specially.
However, this method relies upon accurate abstraction of the content of a
page, which is reliant on the person developing the page. These
fields are often abused by sex or car-The librarian Way
A different method to providing extra information is by setting-up a
library like structure. A few projects try to find solutions
for the massive amount of information this way, for instance
Harvest,
CHOICE,
and DESIRE.
These systems add BibTeX-
Up Main page.