Current Strategies
The main parts of a Spider are
- the page-fetching mechanism;
- the index-building and related search-facility; and
- the user-interface.
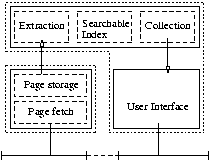 Why should they be so tightly connected as in current implementations?
We can decouple these parts. See the figure left, where the parts
are split. In the figure, the index and user-interface are coupled into
one machine, but this need not be the case.
Why should they be so tightly connected as in current implementations?
We can decouple these parts. See the figure left, where the parts
are split. In the figure, the index and user-interface are coupled into
one machine, but this need not be the case.
When we look at the index-building (`page inventory') and search part, we see a lot of easy-separable functions which can be modularized. The modularization is the opportunity to develop new ideas. Modules can be released to the Public Domain, but there may also be commercial products. To `build' a new Spider you combine a few Public Domain modules, your own modules, and maybe some commercial modules. Run them over the publicly available set of pages, and pass the results to your preferred interface.
This is easy to say but not that easy to implement. Let us now focus on the separate parts of a spider, and see how they could be structured to fit into a m modular system.
The Page-Fetch
We must solve the problem of page-fetching for once and for all. It is totally ridiculous that hundreds of engines access each site. However, it is not feasible to forbid spiders to be built. What is feasible is to collect all data on central machines, placed in tactical locations, and allow everyone to attach to that machine to build their spider.It is not practical to put all of the data on one machine at one point in `The Web'. The exploding amount of information to be found has resulted in existing (centralized) spiders taking too long between visiting a site. One new huge central place will have the same performance problems.
It will be better to arrange things per backbone, per language, or per country (a combination will work best). Of course these are `virtual servers', possibly hosted on the same machine.
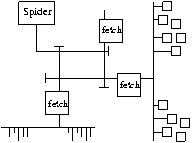 Localized fetching facilities
will improve the quality of the retrievals
because they can be tuned and influenced by people who know about the
local situation. For instance, about what hours are best to scan the sites;
night-time is different everywhere.
The revisiting frequency should be determined by the change-rate of data,
not by the size of `the Net'.
Localized fetching facilities
will improve the quality of the retrievals
because they can be tuned and influenced by people who know about the
local situation. For instance, about what hours are best to scan the sites;
night-time is different everywhere.
The revisiting frequency should be determined by the change-rate of data,
not by the size of `the Net'.
Next to this, more and more pages are made in other languages than English. We have to take into account that more and more Internet users are not able to understand English (and that average American is not able to understand Chinese). The requirement to search "the whole wide World" will decrease. Spiders will localize with it.
Each server (fetcher) repeatedly scans sites on its controlling domain. New spider implementations are informed by the fetchers when they find a changed page which is in the target range of the specific spider. These then fetch their personal copy of this page from the fetcher's storage to process and build their private index with.
Each locally active central fetcher knows were to find the other fetchers. If the storage-server finds pages in a language other than it serves, it passes this data on to an other server which is capable of understanding that language correctly.
To be successful, the fetchers must be open systems. They do not require to be very fast: the update to the spiders will be asynchronous with the site-scan. Techniques can be based on current retrieval software.
Some commercial sites require registration of visitors or even payments. Of course, they want to have as many visitors as they can, but they cannot be searched through by current public spiders. In the structure proposed here, we can build applications who deliver the keywords and description of pages of a closed site to the nearest fetcher, which passes this on. Of course, spiders will ask users if they want to pay for information when a search is made, to avoid disappointments.
Another extension can be made to reduce superfluously checking huge sites with mainly static data. A simple application scans the site locally (so on the system where the data resides) and informs the fetcher which pages changed.
This structure has the following advantages over today's techniques:
- Sites can open their doors to being searched again: the current
reasons for closing (too many requests by spiders, poor implementations) are
resolved. Therefore, participating spiders will get a much better coverage.
- It is easy to build
facilities so that web masters can add information to their sites which
pleases them: how often to scan the site, which authorization should be
used, which parts should be skipped, where it is located physically...
When they have to enter this data only once, they will be more willing to
provide useful data, than when it has to be entered at hundreds
of places. This adds to the trustworthiness of the spider's results.
- Engines are cheaper to build, because they do not need to store all pages
themselves, only to process them into indexes. It is practical to locate
Spiders physically close to the fetchers, but not required.
- On Internet the traffic will be reduced. Don't worry, no doubt it will be filled again in no time with other applications.
The search-index
The searchable index is the main playroom for commercial and non-
Some implementations will prefer to do a lot of work in the extractor, so
the collector has less work and is faster. Some implementations will put
more effort into developing the collector, and avoid wasting computer-
Basically, the extractor and collector will contain a lot of modular
functions. A short description of what is likely to be there:
There are a lot more functions that could be applied to the data which
have no direct relationship to search activities:
Of course, we cannot force everyone to give away their own
implementations of these modules, but a more open attitude will improve
the overall spider's quality.
The User-Interface
The final step is the Human-
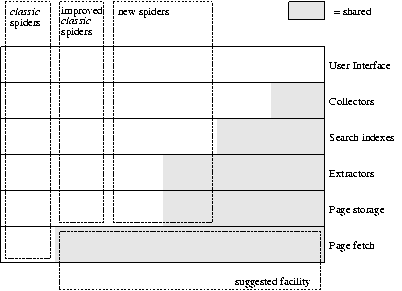
Generalization
In the figure above, a generalization is shown of the private versus open model of spiders. Each spider designer needs to find a balance between private development, public domain parts, and commercial services. For each level of public service, there can be many different implementations.
Next Who Benefits.
Up Main page.