
Indexing Systems
16 of 20start
 |
|||
| Interface Implementation | Layering the Indexing System | ||
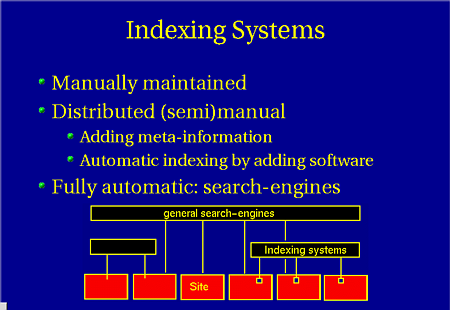
There are three groups of indexing systems on the current Internet:
- the Manually maintained indexes
- where people add site-descriptions, and sites are categorized. Their
usefulness is deminishing, as shown before. An example is
Yahoo!.
- Distributed manual indexes
- are implemented like a library with many places where people
add information to web-pages to improve the retreivability of the
information. Many of these systems exist in the field of research,
like DESIRE, ROADS, etc.
These systems usually require a piece of extra software to be installed on any of the participating web-sites. - Fully automatic indexes
- add the most widely spread. They index all pages (sometimes limited to a country, sometimes the whole Internet), without any manual interference. For example AltaVista.
Mark A.C.J. Overmeer, AT Computing bv, 1999.